为什么需要高性能分布式文件系统
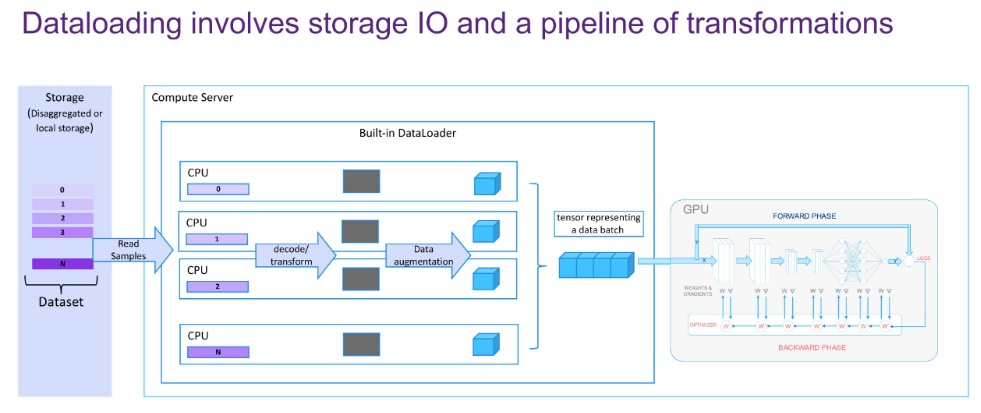
与大多数人的直觉不同的是,在 AI 大模型训练过程中性能瓶颈点是 IO 而不是计算。大模型训练依赖海量数据(如 GPT-3 需要 45TB 文本数据),每个训练步骤需加载数千甚至数万样本(例如图像、视频或长文本序列),数据读取压力远超单机存储或传统网络的吞吐能力。训练 GPT-3 时,单次 Checkpoint 保存需要约 350GB 存储,若每小时保存一次,每天需写入 8.4TB 数据。而现代 GPU(如 NVIDIA A100)的 FP16 算力达 312 TFLOPS,TPU v4 集群算力可达百 PFLOPS 级别,单步计算耗时可能仅需几毫秒。即使使用 NVMe SSD(约 3.5GB/s 带宽),千卡集群的并发读取需求可能高达数百 GB/s,文件存储系统成为喂饱算力的瓶颈。这就好比一个木桶,短的一块板决定了整个系统的能力。
Fire-Flyer 文件系统是什么
The Fire-Flyer File System(3FS)专为应对人工智能训练和推理任务挑战而设计的高性能分布式文件系统。它采用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络技术,构建了共享存储层,极大简化了分布式应用的开发过程。
3FS 的主要特点和优势:
1、性能和可用性
分离式架构。结合了数千个 SSD 的吞吐量和数百个存储节点的网络带宽,使应用程序能够以不受位置限制的方式访问存储资源。
强一致性。实现了带有分配查询的链式复制(CRAQ)以保证强一致性,使应用程序代码简单且易于理解。
文件接口。开发了由事务性键值存储(如 FoundationDB)支持的无状态元数据服务。文件接口广为人知且随处可用。无需学习新的存储 API。
2、多样化工作负载
数据准备。将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
数据加载器。通过支持跨计算节点对训练样本的随机访问,消除了预取或打乱数据集的需求。
检查点保存。支持大规模训练的高吞吐量并行检查点保存。
用于推理的 KVCache。为基于 DRAM 的缓存提供了一种成本效益高的替代方案,提供高吞吐量和显著更大的容量。
3、多应用场景
它支持训练数据预处理、数据集加载、检查点保存 / 重新加载、用于推理的嵌入向量搜索和 KVCache 查找。DeepSeek V3、R1 模型均采用了这个系统。
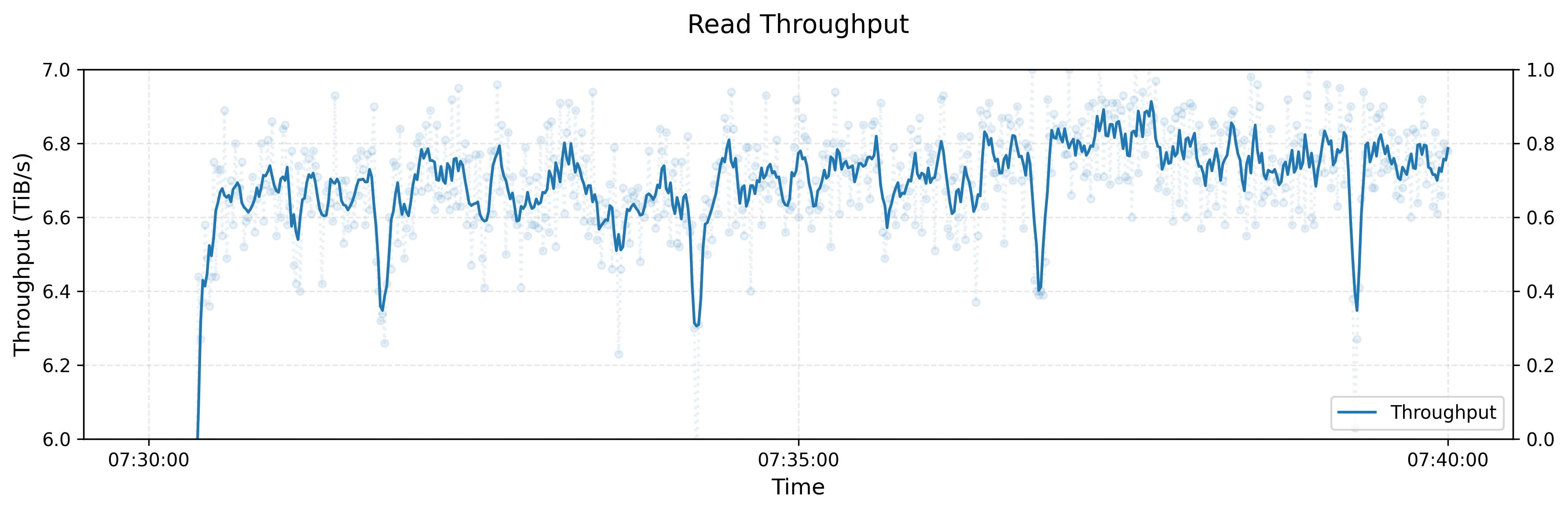
Fire-Flyer 文件系统的性能测试
峰值吞吐量
下图展示了在大型 3FS 集群上进行读取压力测试的吞吐量。该集群由 180 个存储节点组成,每个存储节点配备 2×200Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。大约 500+ 个客户端节点用于读取压力测试 ,每个客户端节点配置 1x200Gbps InfiniBand 网卡。在有训练作业的背景流量情况下,最终聚合读取吞吐量达到约 6.6 TiB/s。灰度排序
灰度排序
DeepSeek 利用 GraySort 基准对 smallpond 进行了评估,该基准可衡量大规模数据集的排序性能。具体实现采用两阶段方法:(1) 使用键的前缀位通过 shuffle 对数据进行分区,以及 (2) 分区内排序。两个阶段都从 3FS 读取数据 / 向 3FS 写入数据。
测试集群由 25 个存储节点(2 个 NUMA 域 / 节点、1 个存储服务 / NUMA、2×400Gbps NIC / 节点)和 50 个计算节点(2 个 NUMA 域、192 个物理核心、2.2 TiB RAM 和 1×200 Gbps NIC / 节点)组成。对 8192 个分区中的 110.5 TiB 数据进行排序耗时 30 分 14 秒,平均吞吐量为 3.66 TiB / 分钟。
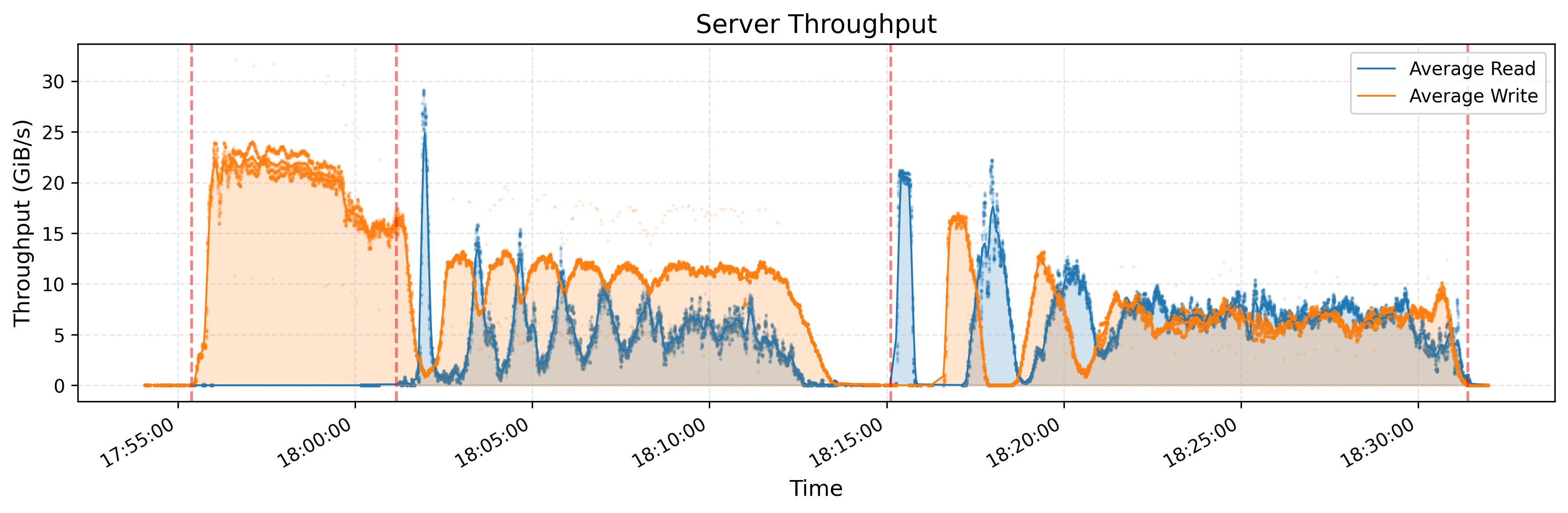
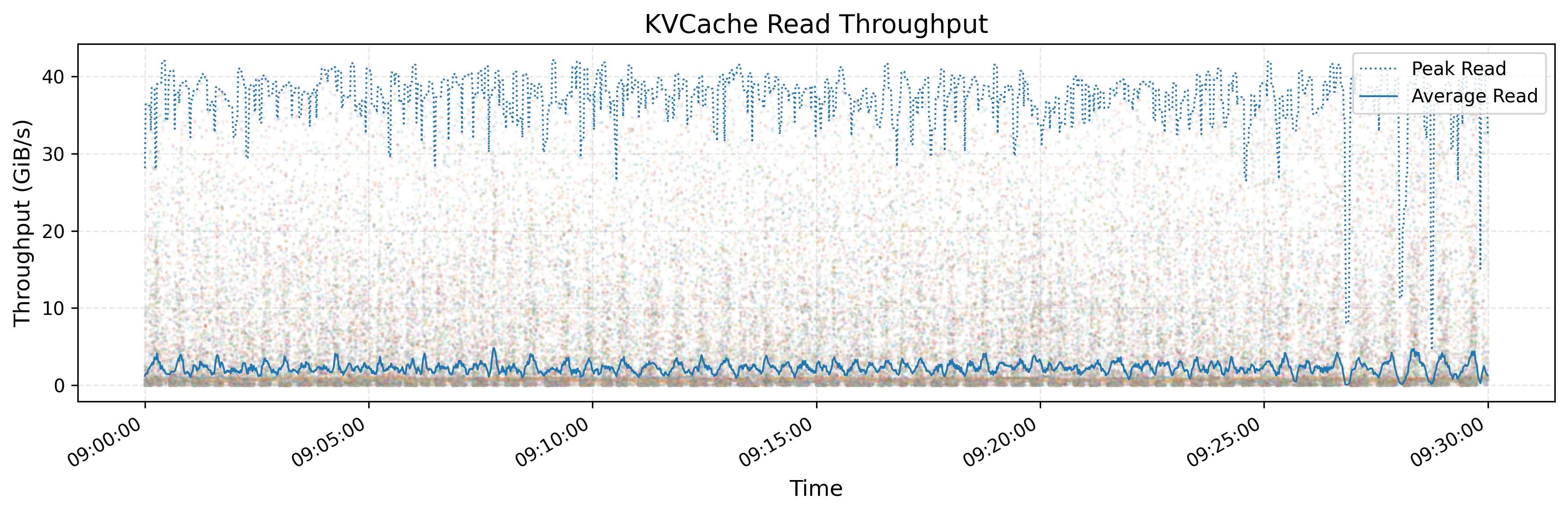
KVCache 吞吐量
这个测试是在 3FS 架构上观测 KVCache 的吞吐量。KVCache 是一种用于优化 LLM 推断过程的技术。它通过在解码器层中缓存先前令牌的键和值向量来避免冗余计算。
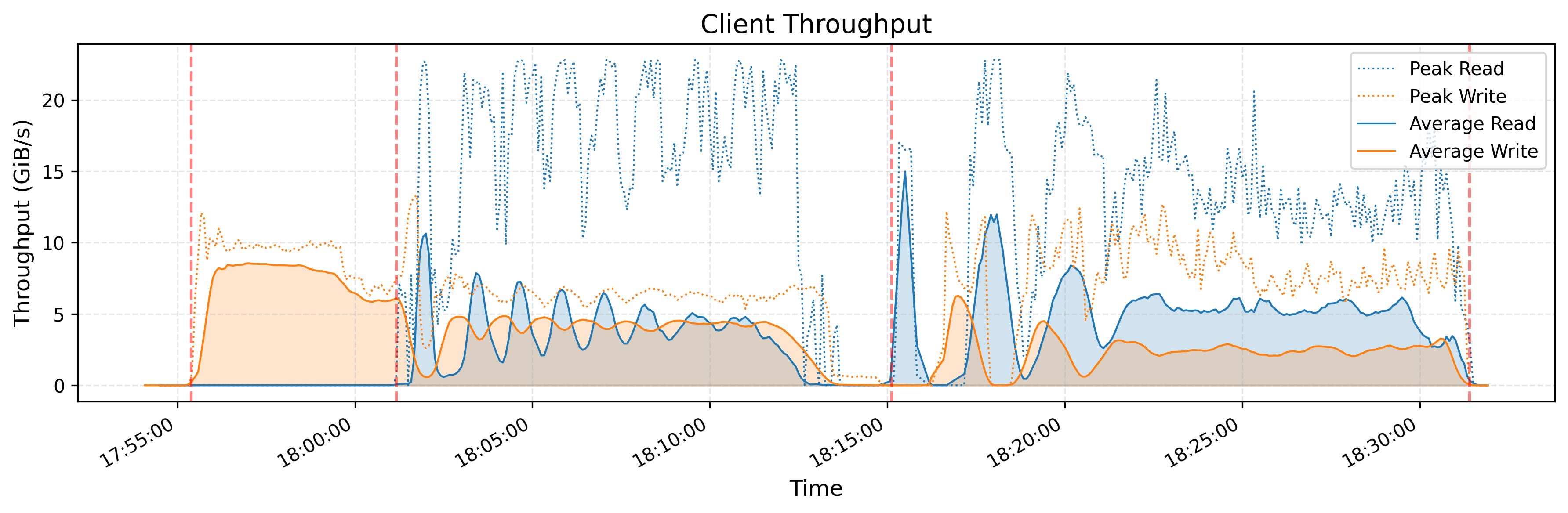
上图显示了所有 KVCache 客户端的读取吞吐量,突出显示了峰值和平均值,峰值吞吐量高达 40 GiB/s。下图显示了同一时间段内从垃圾收集(GC)中移除操作的 IOPS。
构建 3FS
1 下载源码
1 | git clone https://github.com/deepseek-ai/3fs |
2 安装依赖
1 | # for Ubuntu 20.04. |
3 Build 可执行文件
1 | cmake -S . -B build -DCMAKE_CXX_COMPILER=clang++-14 -DCMAKE_C_COMPILER=clang-14 -DCMAKE_BUILD_TYPE=RelWithDebInfo -DCMAKE_EXPORT_COMPILE_COMMANDS=ON |