三句话解释为什么要进行并行策略优化
我们都知道一个简单的道理,让一个人做一百件事和让一百个人分别只做一件事,显然后者的效率更高。大模型训练过程涉及的计算非常复杂,不同策略优化是为了尽可能让大模型计算的过程可以最大程度并行,通过分布式计算将模型或数据拆分到多个设备协同训练,从而提升资源利用率、加速训练过程并实现超大模型的可行性。
DeepEP
DeepEP 是 DeepSeek 专为专家混合(MoE)和专家并行(EP)定制的通信库。它提供高吞吐量和低延迟的全 GPU 对全 GPU 内核,也就是所谓的 MoE 调度和组合。该库还支持低精度操作,包括 FP8。MoE是由多个专家子网络组成的大模型,通过门控网络决定输入分配给哪个专家。
DeepEP提供高吞吐量和低延迟的all-to-all GPU内核,包括MoE分发(dispatch)和合并(combine)。该库支持FP8等低精度运算,特别适用于DeepSeek 系列模型(如 DeepSeek-V2、V3 和 R1)。
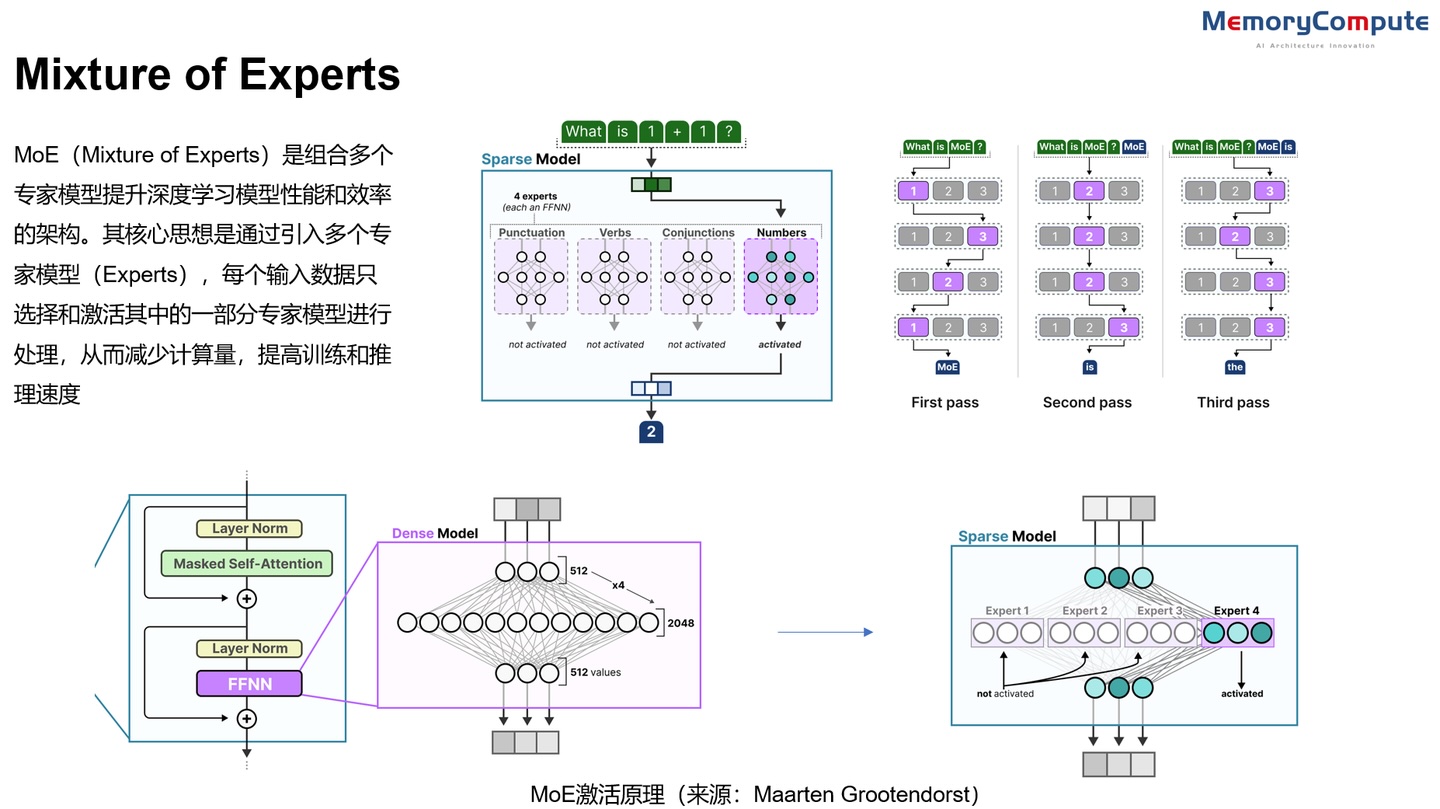
MoE 示意图
很显然,MoE 会涉及将输入数据动态分配给最相关的专家以及整合选定专家的输出,生成最终结果。分发和合并的过程则需要涉及信道的数据传输。DeepEP 针对非对称域带宽转发设计和优化通信内核(例如将数据从NVLink域转发到RDMA域)并提供高吞吐量,使其适用于训练和推理预填充任务。总的来说 DeepEP 主要适用于大模型训练,特别是需要 EP 的集群训练。通过提升通信信道的使用率,提升训练效率。
DeepEP的关键技术
高吞吐量、低延迟的all-to-all GPU内核,专门优化的分派和组合操作。确保数据在多个GPU之间快速传输,减少通信时间。
支持低比特操作,如FP8格式,显著降低计算和存储需求,提升整体效率。
针对非对称域带宽转发(如从NVLink域到RDMA域),提供优化内核,适合训练和推理Prefill任务。允许直接内存访问,减少CPU介入。DeepEP的优化确保数据在不同域之间高效传输,特别适用于大规模混合卡的分布式训练。

CPU 将隐式地等待 GPU 接收到的计数信号
All-to-All通信
通信本身会占用一些计算能力-即 SM(Stream Multiprocessor)的能力,从而影响整体系统性能。DeepSeek V3/R1的训练框架定制了高效的跨节点All-to-All通信内核,以充分利用IB和NVLink带宽,并节约流式多处理器SM。
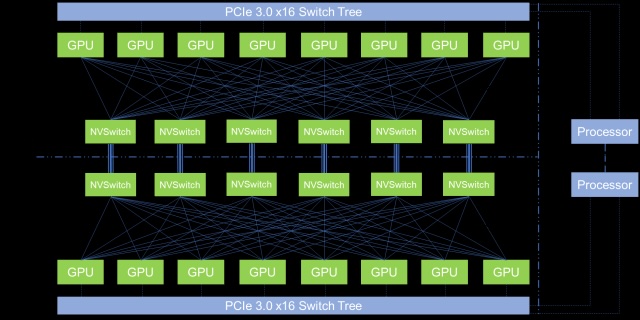
传统的基于NVSwitch的All-to-All通信结构
DeepSeek 采用了warp(线程束)专用化技术,将20个SM划分为10个通信信道。
在调度过程中,(a)IB 发送、(b)IB 到NVLink 转发、(c) NVLink 接收由相应的warp处理。分配给每个通信任务的warp数量会根据所有SM的实际工作负载动态调整。
在合并过程中,(1) NVLink 发送、(2)NVLink到IB的转发和累积、(3)IB接收和累积也由动态调整的warp处理。
dispatching 和combining kernel都与计算流重叠,采用定制的PTX(Parallel Thread Execution)指令以自动调整通信块大小,减少了对L2缓存的使用和对其他SM的干扰。
**NVLlink / NVSwitch / InfiniBand/**RDMA
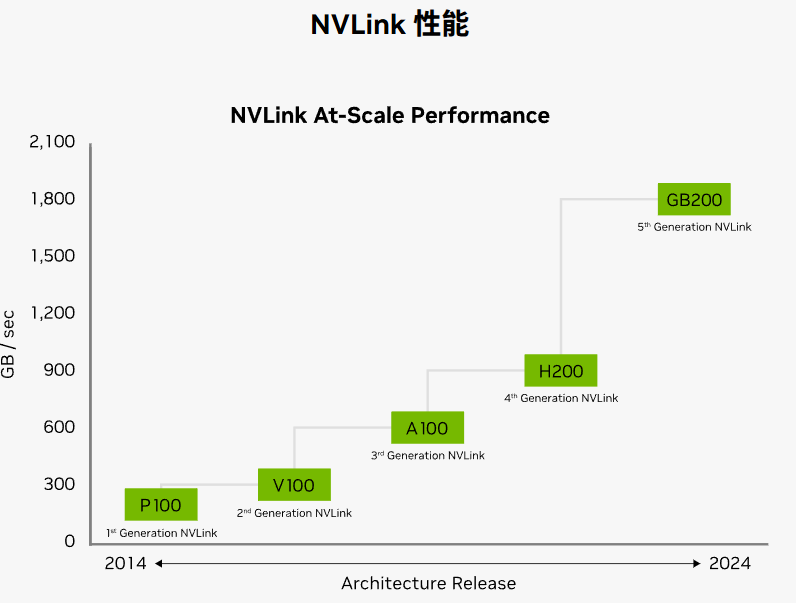
NVLink 是一种专门设计用于连接 NVIDIA GPU 的高速互联技术。 它允许 GPU 之间以点对点方式进行通信,绕过传统的PCIe总线,实现了更高的带宽和更低的延迟。NVLink提供高达300GB/s的带宽,是PCIe的10倍,可用于GPU间、GPU与CPU间的通信,甚至CPU互联 。
NVSwitch 是一款GPU桥接设备(芯片),可提供所需的NVLink交叉网络,以初代NVSwitch为例,每块NVSwitch提供18个NVLink端口,支持直连多块GPU,提供GPU之间的高速互联。
InfiniBand(直译为 “无限带宽” 技术,缩写为IB)是一个为大规模、易扩展机群而设计的网络通信技术协议。Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输。InfiniBand 最重要的一个特点就是高带宽、低延迟,因此在高性能计算项目中广泛的应用。 主要用于高性能计算(HPC)、高性能集群应用服务器和高性能存储。在目前的大模型训练集群中 InfiniBand 通常用于不同计算节点之间的互联
RDMA(远程直接数据存取)就是为了解决网络传输中服务器端数据处理的延迟而产生的,无需使用CPU,就可以从一个主机或服务器的内存直接访问另一主机或服务器的内存。它释放了CPU去执行其应做的工作,比如:运行应用程序和处理大量数据。这既提高了带宽又降低了延迟、抖动和 CPU 消耗。RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到1us以下。同时,RDMA的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了CPU的负担,提升CPU的效率。
DeepEP 的性能表现
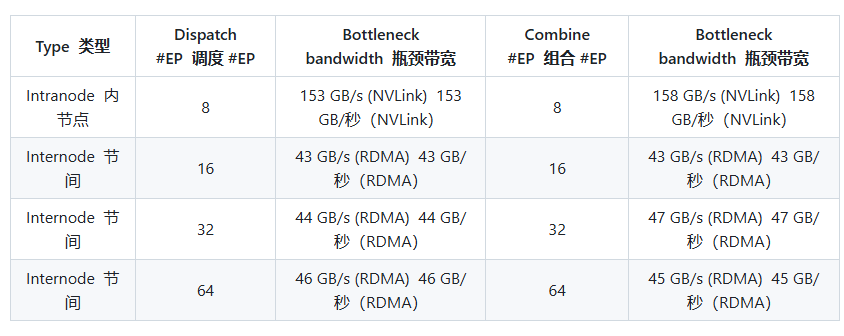
带有 NVLink 和 RDMA 转发功能的 Normal kernels
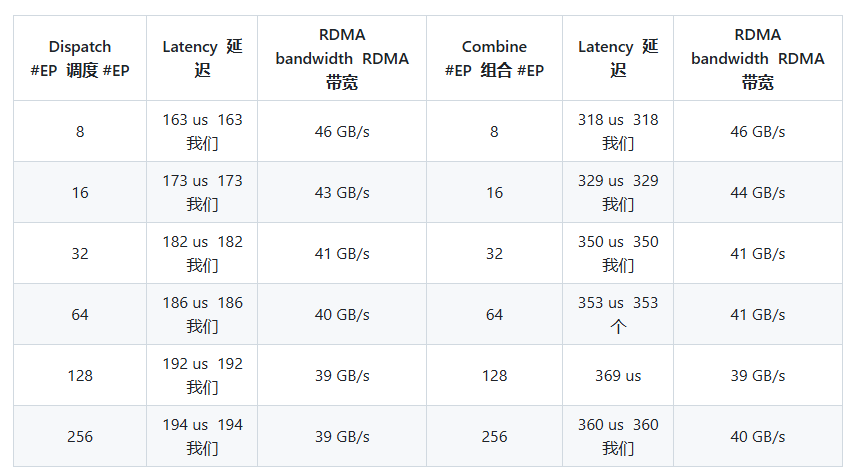
在 H800(约 160 GB/s NVLink 最大带宽)上测试普通内核,每个内核都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(约 50 GB/s 最大带宽)。采用 DeepSeek-V3/R1 预训练设置(每批 4096 个 Token、7168 个隐式 Token、前 4 组、前 8 个专家、FP8 调度和 BF16 组合)。
Pure RDMA 的低延迟内核
在 H800 上测试低延迟内核,每个内核都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约为 50 GB/s)。D采用典型的 DeepSeek-V3/R1 生产设置(每批 128 个 Token、7168 个隐藏 Token、前 8 名专家、FP8 调度和 BF16 组合)。
DualPipe
DualPipe 是 DeepSeek-V3 技术报告中提出的一种创新的双向流水线并行算法。它实现了前向和后向计算-通信阶段的完全重叠,同时也减少了流水线气泡。(流水线气泡(Pipeline Bubble) 指由于不同设备(如GPU)之间的处理速度不均衡或通信延迟,导致部分设备在等待数据时处于空闲状态,形成“气泡”,从而降低整体的计算资源利用率)
DualPipe具有以下核心特点:
1)计算与通信重叠
DualPipe 的设计目标是最大化集群设备的计算性能,通过在前向传播(Forward)和后向传播(Backward)阶段实现计算与通信的完全重叠,显著减少传统流水线并行中的“气泡”(Pipeline Bubble,即空闲等待时间)。这对于需要跨节点协作的专家并行(Expert Parallelism)场景尤为重要。
2)双向调度
与传统的单向流水线并行不同,DualPipe 采用双向调度策略,从流水线的两端同时输入微批次(Micro-batches),充分利用硬件资源。这种方法在保持计算通信比例恒定的情况下,即使模型规模进一步扩大,也能维持接近零的通信开销。
3)高效扩展性
DualPipe 针对跨节点的混合专家模型(MoE)进行了优化,通过减少通信瓶颈,使得大规模分布式训练能够在相对有限的硬件资源(如 H800 GPU)上高效运行。
4)显存优化
DualPipe 将模型的最浅层(包括嵌入层)和最深层(包括输出层)部署在同一流水线级别(PP Rank),实现参数和梯度的物理共享,进一步提升内存效率。这种设计减少了高代价的张量并行(Tensor Parallelism)需求。
专家并行负载均衡器 (EPLB)
在使用专家并行(EP)时,不同的专家被分配到不同的 GPU 上。由于不同专家的负载可能因当前工作负载而异,因此保持不同 GPU 的负载均衡非常重要。正如 DeepSeek-V3 论文中所述,他们采用了冗余专家策略,复制负载较重的专家。然后,启发式地将复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载均衡。此外,基于 DeepSeek-V3 中使用的组限专家路由,尽可能将同一组的专家放置在同一节点上,以减少节点间的数据传输。
负载均衡算法附带两种策略,用于不同场景。
层级化的负载均衡
当服务器节点数整除专家组数量时,可以采用分层负载均衡策略来利用组限专家路由。首先,将专家组均匀分配到各节点,确保不同节点的负载均衡。接着,在每个节点内复制专家。最后,将复制的专家分配到各个 GPU,以确保不同 GPU 之间的负载均衡。分层负载均衡策略可在预填充阶段使用,此时专家并行规模较小。
全局负载均衡
在专家并行规模更大的情况下,更适合采用全局负载均衡策略,该策略无视专家组的划分,将专家在全球范围内复制,并将这些复制的专家分配至各个 GPU。
如何使用
以下代码展示了一个包含两层的 MoE 模型示例,每层包含 12 个专家。DeepSeek在每层引入 4 个冗余专家,总共 16 个副本分布在 2 个节点上,每个节点包含 4 个 GPU。
1 | import torch |
以下展示了由层级化负载均衡策略生成的专家复制和放置策略
