DeepGEMM 亮点的简要解释:
⚡ Up to 1350+ FP8 TFLOPS on Hopper GPUs | ⚡ Hopper GPU 的 FP8 TFLOPS 高达 1350+
基于英伟达Hopper架构GPU的FP8(8位浮点)计算能力峰值超过1350万亿次/秒,充分发挥低精度计算的高效性,显著加速大规模模型训练与推理。✅ 极简设计
代码库设计极简,无需依赖复杂第三方库,降低部署和维护成本,同时提供类似教程的清晰结构与可读性。✅ 完全即时编译
所有计算逻辑支持运行时即时编译(JIT),动态适配硬件环境并优化执行路径,避免预编译的兼容性问题,提升灵活性与性能。✅ 核心逻辑仅约300行,性能仍超越专家调优的内核
通过算法创新(如高效算子融合与内存管理),以极简的代码实现超越手工优化计算核心的性能,兼顾可维护性与高效性。✅ 支持密集布局与两种混合专家(MoE)布局
兼容传统密集计算模式与MoE稀疏化扩展架构(如块状/动态专家分配),灵活适配不同模型设计需求,尤其适合千亿参数级大模型。
DeepGEMM 是什么
GEMM(General Matrix Multiplications)即通用矩阵乘法,是将两个矩阵的进行相乘的计算。DeepGEMM 是一个专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计的库,具备细粒度缩放功能,如 DeepSeek-V3 中所提议。它支持普通及混合专家(MoE)分组的 GEMM。该库采用 CUDA 编写,安装时无需编译,所有内核均通过轻量级的即时(JIT)模块在运行时编译完成。
目前,DeepGEMM 仅支持 NVIDIA Hopper 张量核心。为了解决 FP8 张量核心累积不精确的问题,它采用了 CUDA 核心的两级累积(提升)方法。虽然它借鉴了 CUTLASS 和 CuTe 的一些概念,但避免了对它们模板或代数的重度依赖。相反,该库设计简洁,仅包含一个核心内核函数,代码量约为 300 行。这使其成为学习 Hopper FP8 矩阵乘法及优化技术的清晰且易于获取的资源。
尽管设计轻巧,DeepGEMM 在各种矩阵形状下的性能与专家调优的库相当或更优。
背景知识 - GEMM与TensorCore
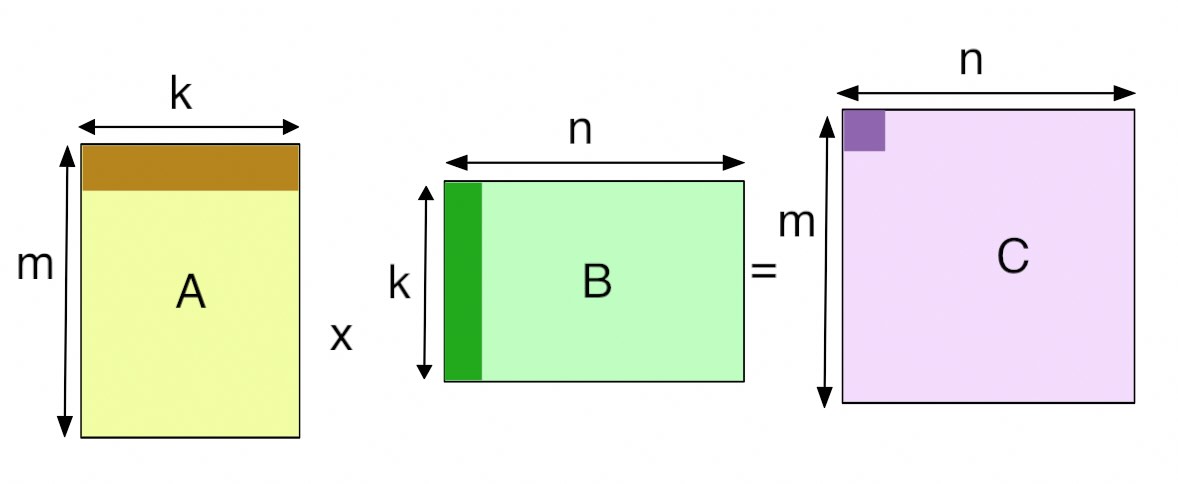
在GPU中,GEMM 定义为运算C=αAB+βC
其中 A 和 B 作为矩阵输入,α 和 β 作为标量输入,C 作为预先存在的矩阵,被输出覆盖。普通矩阵乘积 AB 是 α 等于 1 且 β 等于 0 的 GEMM。例如,在全连接层的正向传递中,权重矩阵为参数 A,传入激活为参数 B,α 和 β 通常分别为 1 和 0。在某些情况下,β 可以是 1。
GPU 通过将输出矩阵划分为图块来实现 GEMM,然后将其分配给线程块。图块大小(Tile Size)通常是指这些图块的尺寸。每个线程块通过单步执行图块中的 K 维度,从 A 和 B 矩阵加载所需的值,然后将它们相乘并累加到输出中来计算其输出图块。
鉴于矩阵运算,尤其是矩阵乘法如此重要,英伟达 GPU 引入了 Tensor Core(张量核心) 来最大限度地提高GEMM的速度。第一代 Tensor Core 是随 Volta 架构引入的,从 V100 开始,随着数据格式的变化,Tensor Core也在不断更新。
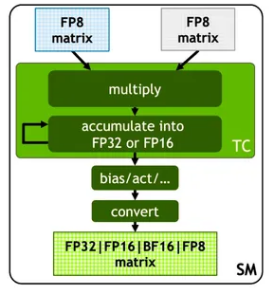
GEMM 在 TensorCore 基础上对 FP8 的改进
细粒度量化
将数据分解成更小的组,每个组都使用特定乘数进行调整以保持高精度。这一方法类似于Tile-Wise或Block-Wise。对于激活运算,在1×128大小的基础上对计算数据进行分组和缩放:对于权重运算,以128x128大小对计算数据进行分组和缩放。该方法可以根据最人或最小数据调整缩放系数,来更好的适应计算中的异常值。
在线量化
为了提高精度并简化框架,该框架在线计算每个 1x128 激活块或然后将激活或权 128x128 权重块的最大绝对值,在线推算缩放因子,然后将激活或权重在线转化为 FP8 格式,而不是采用静态的历史数据。相对静态的量化方法,该方法可以获得更高的转换精度,减小误差的累积。
提高累加精度
FP8 在大量累加时会累积出现随机误差。例如 FP8 GEMM 在英伟达 H800 GPU 上的累加精度保留 14 位左右,明显低于 FP32 累加精度。以 K=4096 的两个随机矩阵的 GEMM 运算为例,Tensor Core中的有限累加精度可导致最大相对误差接近 2%(32位浮点)。DeepSeek 将中间结果储存计算升级为 FP32(32位浮点),实行高精度累加,然后再转換回 FP8,以降低大量微小误差累加带来的训练。
低精度/混合精度存储与通信
为了进一步减少 MoE 训练中的显存和通信开销,该框架基于 FP8 进行数据/参数缓存和处理激活,以节省显存与缓存空间并提升性能,并在 BF16(16位浮点数)中存储低精度优化器状态。该框架中以下组件保持原始精度(例如 BF16 或 FP32):嵌入模块、MoE 门控模块、归一化算子和注意力算子,以确保模型的动态稳定训练。为保证数值稳定性,以高精度存储主要权重、权重梯度和优化器状态。