DeepSeek 开启了炸裂的开源周,没有任何遮遮掩掩,成为了的的确确的 “OPEN AI”。满满的干货必须配上深入解读,才能吸收的更好。让我们来一起拥抱 DeepSeek 的开源美学!
FlashMLA 特点
BF16 支持,支持 BF16 数据类型,在降低显存占用的同时保持模型训练/推理精度,尤其适合大规模模型的高效计算。
Paged KV cache (block size 64),采用分页式键值缓存管理(块大小64),按需动态分配显存块,减少内存碎片并提升长序列推理的吞吐量。
极致性能,在H800硬件上,内存密集型任务带宽达3000GB/s,BF16计算峰值达580万亿次/秒,兼顾高吞吐与低延迟的负载需求。
概念介绍 - 从 KVCache 谈起
KVCache
传统 Transformer 在推理(inference)过程中计算并生成下一个 Token 时,模型需要根据过去所有的 Token 上下文作为条件来计算。这样一来每输出一个 Token 都需要把之前的 n-1 个 Token 都再计算一遍。为了能节省这部分重复计算,目前常用的方法就是缓存计算过的内部状态,也就是缓存注意力机制中的 Key 和 Value 矩阵,这也是 KV Cache 名称的由来。对于 Transformer类的大模型来说,由于KV Cache巨大,很难直接放在Cache里,需要放在HBM 或 GDDR 上,并在计算过程中频繁挪动 KV 数据。这时就会出现 Memory Bound(存储限制)的情况,极大影响了 KV Cache 的吞吐带宽和大模型的计算速度。
MLA
MLA (Multi-head Latent Attention)是 DeekSeek 对多头潜注意力机制的一种改进。能够在不影响计算有效性的前提下极大减少内存占用,它通过低秩矩阵压缩 KV Cache(键值缓存),减少内存占用,同时提升模型性能。
FlashMLA
借鉴 FlashAttention 分块 Tiling 和显存优化的思想。通过以算代存减少对于显存带宽的要求,提升计算性能。FlashMLA是MLA技术和Flash Attention技术的结合,可以认为是Flash Attention的MLA版本。
FlashMLA 的正确打开方式
系统要求
- Hopper GPUs Hopper GPU
- CUDA 12.3 and above CUDA 12.3 及以上版本
- 强烈建议使用 12.8 或更高版本,以获得最佳性能
- PyTorch 2.0 and above PyTorch 2.0 及以上版本
安装
1 | Python setup.py install |
基准测试
1 | python tests/test_flash_mla.py |
使用 CUDA 12.8,在 H800 SXM5 上实现高达 3000 GB/s 的内存绑定配置和 580 TFLOPS 的计算绑定配置。
使用方法
1 | from flash_mla import get_mla_metadata, flash_mla_with_kvcache |
FlashMLA核心技术深入理解
MLA的本质是对KV的有损压缩,提高存储信息密度的同时尽可能保留关键细节。该技术首次在DeepSeek-V2中引入,与分组查询和多查询注意力等方法相比,MLA是目前开源模型里显著减小KV 缓存大小的最佳方法。
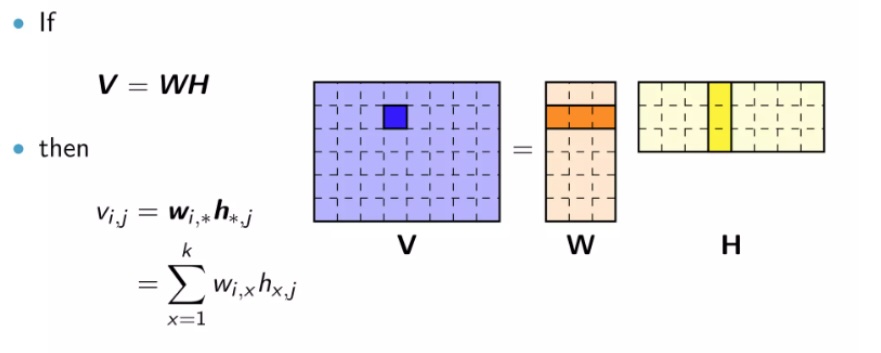
MLA的方法是将KV矩阵转换为低秩形式:将原矩阵表示为两个较小矩阵(相当于潜向量)的乘积,在推断过程中,仅缓存潜向量,而不缓存完整的键KV。这规避了分组查询注意力和多查询注意力的查询的信息损失,从而在降低KV缓存的前提下获得更好的性能。
MLA虽然在设计上非常巧妙,但没有类似加速框架的 FlashAttention 或 PageAttention 解决方案。这也使得DeepSeek R1在实际部署时需要单独优化KV吞吐性能。
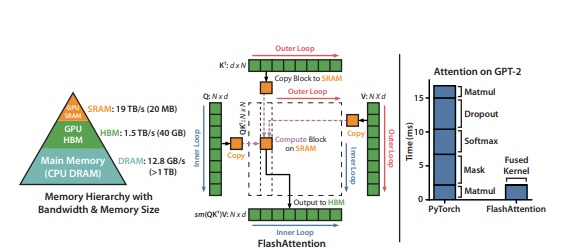
FlashMLA 正式借鉴了 FlashAttention 的设计思路在硬件层面进一步提升 MLA 的计算效率,其关键技术包括:
- 低秩矩阵压缩:MLA 使用低秩矩阵,将KV缓存压缩为潜向量,减少内存占用。通过解压潜向量生成独特的KV头(KV Head)
- 针对GPU 优化:FlashMLA针对Hopper GPU 的Tensor Core进行youh优化,实现了可达3000 GB/s 的显存带宽和 580 TFLOPS 的计算性能(H800 SXM5 配置)。使用了SM90的关键特性GMMA、namedbarrier同步、cp.async。
- Row-wise/Block-wise优化:细粒度划分,在shared memory中原位处理计算,减少了额外的中间计算过程的显存占用,减少显存访问次数。
- Split-KV 分块处理:将KV拆分给多个SM(Stream Multiprocessor)处理(或者多次迭代),然后在局部把partial计算结果合并。
- 变长序列支持:通过 tile_scheduler_metadata 和 num_splits 参数,,FlashMLA 支持变长序列的并行处理,以缓解负载不均衡问题。
FlashMLA的价值与意义
FlashMLA 是 DeepSeek 团队在 AI 性能优化领域的重要成果,实现了在英伟达Hopper架构GPU的高效Inference。其价值在于:
- 对自家的 MLA 做了硬件层面的定制优化,使得 MLA 的性能更加极致
- 充分鼓励开发者优化或适配其他硬件,使得整个大模型生态更加丰富